Published on 7/8/2019
In this part, we start to look at the final part of the Publish verb - pushing content to different social media outlets. This will be the hardest task we’ve done so far, and it requires some upfront research first. Understanding the problem that you need to solve is much more important than trying to design a solution (This is also true when you’re all about your startup idea). That makes logical sense of course, but I’ve often seen developers barely finish reading the user story's first line, and they are already furiously typing up code or drawing database and architecture diagrams, believing they ‘see the big picture’. And sometimes that might be true. Perhaps they’ve solved a similar problem before or they have lots of experience in a domain industry like fintech. But neglecting the details and the exceptions (stuff like edge cases for example) will always result in rework. And often that rework takes the form of what I like to call “programming through permutations”. This is when the code almost works but the developer is not sure why it breaks on a particular use case or edge case. And what you’ll often see is that they will make a small change and test, make another small change and test again, rinse and repeat, until it works. Often this can take up an entire afternoon, simply moving bits of code around or changing greater-than comparisons to greater-than-equal ones. And when it finally works they still have no idea why it broke or how their final change caused it to work.
Plowing through the API documentation
So in order to understand this problem, we need to see what we will face at the various social media outlets. That is, what are the requirements for each social media syndication, and how do they overlap. Our work here will not involve dealing with the respective social media APIs directly yet (we have an abstraction for that), but we do need to understand what these APIs will accept, and so what it is our abstraction IBlogSyndication will have to support as a minimum. For now, I’m going to concentrate on RSS, Twitter, and Facebook. I don’t have an Instagram account (I’m old, hey).
RSS
RSS doesn’t have an API of course, it’s just a standard (or a convention, if you will). It has an official specification and they provide some sample documents, just the thing I need. There’s the channel with some details on it and a bunch of items inside the channel. Think about these channels literally as channels on the TV. If you have the DStv app on your phone, it probably uses some extension of RSS (or something very similar) to convey that data to the app. I might only have one channel, or I might make a channel per project. Each item has only a few values: title, link, description, publish date and a Guid. Now we already have a small set of properties that our candidate blog syndication model must support, and I can already guess that the Guid will have to be persisted. But RSS works differently from social media services. RSS is a reactive thing, that is, it reacts to someone that wants to read from it, as opposed to me posting something somewhere into the cloud. Typically I will have a link to my site like https://www.helloserve.com/rss, and this will serve an XML file like that sample page with all the details in it. Who-ever (or what-ever) reads that XML can then decide how to display it or make sense of it according to the standard. For example, you can add my RSS link to your Feedly account, and it will read the channels and items and decide how to display it to you within their app experience. In order to do that I have two options. Prepare an XML file beforehand and just load it up whenever someone visits that link, or generate the XML file on demand from prepared data and serve it. We’ll talk about this later again, but here’s a spoiler: the first option is really the same as the second option with some tweaks.
I came upon the POST statuses/update API reference within a few minutes of searching. Without worrying about stuff like authentication and so on, the list of parameters show quite a few items that go into the POST. The important one appears to be status. Yep, there is only one. We can include an image perhaps, but the link to our blog post will have to be inside the status (or the tweet) itself. So it seems that we will have to construct the final value of status from different parts of the blog. This will be proactive syndication, meaning I will have to call their API and deliver the content to them. It’s easier in the sense that I don’t have to persist anything, but it’s harder in that I will have to deal with HTTP failures and other problems.
And finally, the daddy. Unfortunately, I think we’re going to have some trouble here. Facebook has plenty of official SDKs, but not one for C#. That’s expected, actually (C# is still considered a “for corporate” language by most). Microsoft maintains a UWP app SDK however, so that might work. But here’s the thing, on Facebook I have a page for helloserve Productions, and I want to syndicate to this page instead of to my own profile (I typically share what I post to the page). However, the Business SDK, which has the this page deals with publishing to (or as) a page. It appears that there are only two values to set as query parameters: message and link. So this is very similar to the Twitter API.
Where is the overlap?
Now that we have an idea of the problem, we can design a solution for it. I really only need two things for the social media posts: the text, and the link. For RSS on the other hand, there is a title and a separate description. So where is the intersection between these syndications? Twitter has a strict limit on length, and any sort of general description is probably going to be too long. I think this explains why you typically see standard messages like “I posted a video to youtube” with the related link. Facebook, on the other hand, will accept a large piece of text and is only limited by the maximum length of a URL. But here is another consideration: when you manually make a post on Facebook, and you paste in a URL, Facebook automatically shows you a card for that link, sometimes with an image, sometimes with a “blurb”. How does that work? Some googling show me that it relies on metadata within the HTML page of the source. So now we have title and description again, albeit within the actual blog post’s HTML page.
Base it in reality
In order to decide how I’m going to overlap these three syndications, I’m going to look at some of my old content compared to other’s content. In my old blog posts, I typically had a “cut” as a first paragraph. This was also what I display in my blog ‘cards’ on my site, together with the title. It was actually a completely separate column in the News table and represented as a separate paragraph in the HTML page. At the time Facebook typically looked for the <h1> tag and the first <p> tag when you pasted a link as a post, and that’s what I did then. So I actually already have this concept of a title and a description in my current blog data. Now let’s look at a syndicated tweet:
This looks a lot like the new Volkswagen Golf 8 undergoing final tests. What do you think: https://t.co/ofDTdShJ0K pic.twitter.com/y36X8A3Cue
— Cars.co.za (@CarsSouthAfrica) March 8, 2019
The article that this links to does not contain the text in the tweet at all. In fact, this tweet appears to have been manually authored. But the amount of metadata in that HTML page of that article is phenomenal. That’s a good learning. Another example:
McLaren's customer-ready Senna GTR has been unveiled with updated aero - https://t.co/OZV2A9sT0g #McLaren #McLarenSennaGTR pic.twitter.com/IZI6GFoqic
— evo magazine (@evomagazine) March 8, 2019
Compare this to the same article’s Facebook post:
They use the same text, save for the hashtags, but it doesn’t appear in the meta tags of the actual article page.
So I’m thinking instead of trying to “overlap” these different pieces of information, perhaps I should actually separate them and just help myself out with good UI. Meaning, I should provide myself space in the authoring of the blog post to put in the text I want to use as a tweet, and as a Facebook post. The UI can pre-populate it as soon as I fill in the description field. Then I can separately edit the field for Twitter to shorten it or include hashtags for example.
SOLID: S for Single Responsibility
But this gives me another problem. I don’t want to litter my blog model with disparate fields about social media posts. And I certainly don’t want to carry along data in my database that would live there and never be used again. On a higher level, the entire concept of the blog should have a single responsibility. And the syndication abstraction should inform the rest. I need to devise another way to capture and process these bits of text that will accompany the various social media posts without having to persist it in the database or domain models.
So here’s my idea: The front-end receives data from configuration that informs the page about the various options for syndication, and generates the required UI for each one. The ones I fill in are then sent back to the API and arrives at the Publish method separately from the blog model. This is then transformed into different instances of the IBlogSyndication abstraction through a syndication factory, and then the captured fields are passed to the related instances for processing in the background service.
Plan it
I think now we have a final list of items that we need to support, so let’s plan our work for this. We have enough to complete the Blog entry, and we can add most of these properties on it. But how do we test it? Do we even test it? Simply adding a property doesn’t warrant a unit test. There’s no code there, except the declaration. And you only unit test code that your write. Next, I think we can fill in our abstraction IBlogSyndication a bit too, and then we can test that we make use of it, somehow. But now comes the tricky part - in order to make use of it, we need an out-of-process way to call three different instances of the same adaptor. You’ll recall from our flow diagram in part 5 that we branched off into the “process” column, where we had a loop that pushed to the various adaptors. This was surrounded by a box labeled IHostedService.
Concept: Asynchronous vs Background
Let's talk about asynchronous flow first. Simply put, when the incoming web request completes (you responded back to it), the .NET Core runtime shuts down the thread that handled that request to make it available for the next request. So it signals to the stack, using a CancellationToken, that it’s finished and wrapping up. If you launched any Tasks without awaiting them, they are gone and completion of those tasks are not guaranteed, meaning they might exit based on the token, or they might not (often null is passed as the token). And we don’t want to hang around waiting for a list of syndication processes to get done while our user that published a blog post has to wait for the screen to load. We want to process these syndications completely out of band, while responding to the user as quickly as possible.
We can achieve this by using the System.Threading API in conjunction with a singleton service, but I’ve seen posts about the .NET Core IHostedService API and I want to see what this is all about. It turns out that even the WebHost that we use when we build our API (see the Program.cs file) is based on this API. That page details three different implementations, and the one I’m interested in is the queued background tasks one. Three things are required:
- A singleton queue manager,
IBlogSyndicationQueue. This is behind an abstraction because it is constructor-injected into theBlogBackgroundServicetogether with a logger. - A background processor
BlogBackgroundServicethat extends BackgroundService. This in turn implementsIHostedService. - I have to worry about setting up a scope so that the syndication can make use of dependency injection to get other services, like
HttpClient.
Tests
The singleton queue manager concrete has to do two things: queue and dequeue. The background service has to poll the queue, take items and process them. And then the blog service, when publishing, has to invoke the queue using the scope to put items onto it. Lets list these.
- Test queue operation on BlogSyndicationQueue
- BlogSyndicationQueue_Enqueue
- BlogSyndicationQueue_Dequeue
- Test BlogBackgroundService process
- Dequeue and process queued items
- BlogBackgroundService_Process
- Test BlogSyndicationFactory
- Return correct instance based on input from configuration
- Test that BlogService enqueues as many syndications as configured
- Should be generic Action that invokes functionality on IBlogSyndication abstraction
- Define and read config
- BlogService_Publish_EnqueueSyndications
All of this can be depicted as follows:
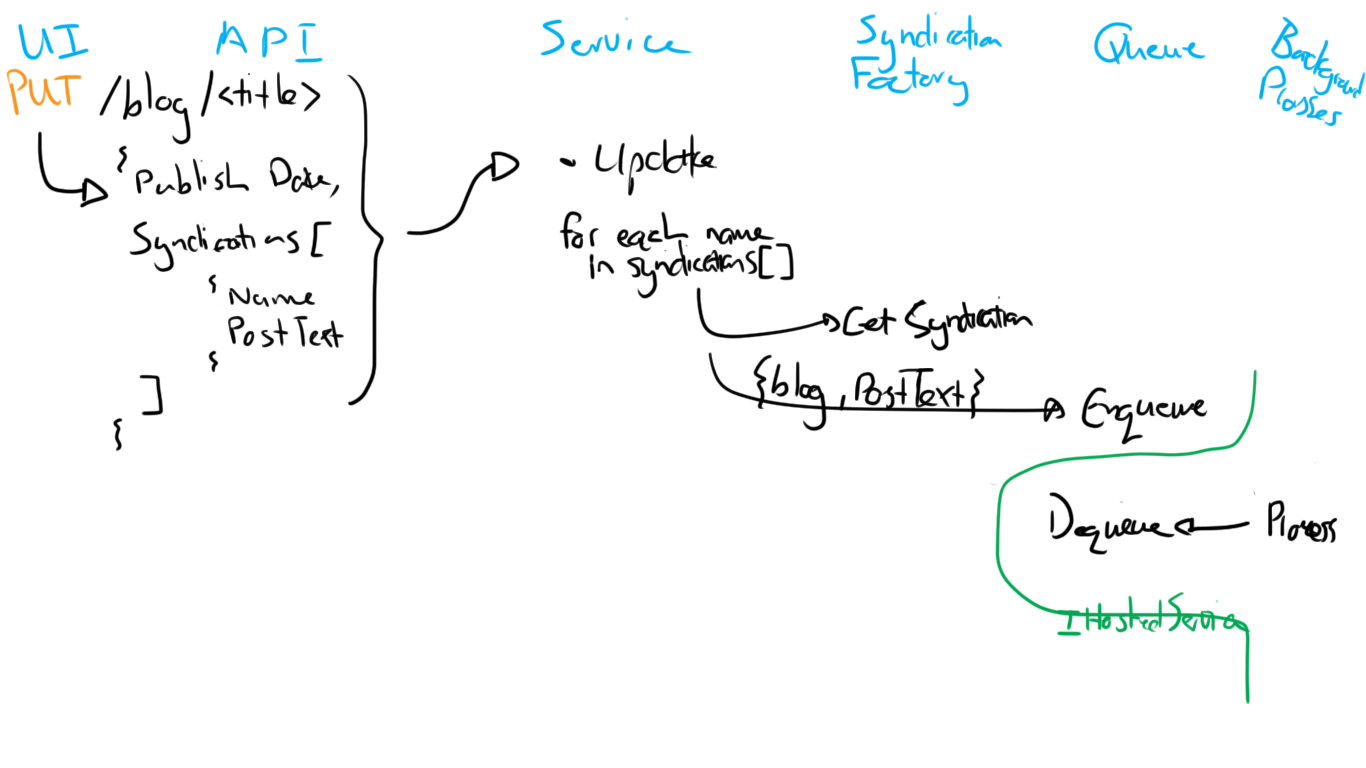
This flow diagram looks slightly different from the previous one, but it still has all the same parts (I left out the repo due to space). This evolution of the one from part 5 was informed by my deeper understanding of the problem. In part 5 I had already included in the initial plan some tests related to the syndication configuration, hosted service and so on. Those remain valid of course, but again have been evolved due to my additional understanding of the problem in this part.
Concept: Extensibility
Maybe you’re wondering why the queue service is abstracted by an interface, since it is entirely feasible to just register a class as a singleton and stick that into the constructor. And for a narrow implementation like this blog that will be fine. But consider this: in a broader system where you have more mission critical things happening, you don’t want that queue to die when something happens to your API instance. So while this example implements a concrete around the ConcurrentQueue collection, in real life this type of implementation will probably focus around a RabbitMQ instance which will be running as a separate service. In this way your queue is persisted outside of the API service, which is a much more robust design. Here is a separate, very detailed overview of queues and implementations of it. Then there are the following to consider.
SOLID: D for Dependency Inversion
Since we’ve practiced this a few times now you should be familiar with the idea of providing an abstraction for the queue service that decouples the blog domain from the queue implementation. The BlogService has no dependency on the specific queue implementation details.
SOLID: L for Liskov Substitution
Additionally, we see how we can provide different implementations by using an abstraction, but have the same results. In your development environment you can start the API service with an in-process implementation of the queue and expect a specific behavior. Then during user testing and later in production, you can start the API with a more resilient implementation around a separate, persisted service, and still expect the exact same behavior. Different concrete implementations that adhere to the contract defined by the abstraction.
Conclusion
This part has taken much longer to complete than I anticipated, so we’re not going to write any code now. But it was a most interesting part to research. We’ve seen how it becomes necessary to deep dive into the domain that you’re working in and how you have to understand and follow through on the concepts and processes within the scope of your problem. Figuring out the solution is a natural progression when you understand the problem, and so we’ve evolved our process flow (your client will also show much appreciation of your demonstrated understanding of their problems). We’ve also discussed and contemplated different background workers and different queue implementations. Both these concepts are crucial elements in any moderately complex IT-system, and they come in many different shapes and forms.