Published on 5/14/2019
Since we’ve completed our solution architecture’s design, we can now start putting an actual solution together in Visual Studio. But what will our starting point be?
Bottom up, top down, or?
Either approach is correct of course - we're not limited by physics. It all depends on what you have designed in enough detail at this point that will allow you to start on the code. In this series so far we have deferred all the decisions by using abstractions, so the only part that we can code now is the core of the blog domain. Let's put a solution together for that:
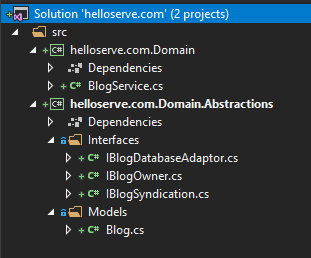
.Abstractions
There are two projects here, and one of them is the cross cutting, or common, or shared bits that everything is dependent on. This is post-fixed with ".Abstractions" and separated out from the main domain project. I do this because again, it isolates those elements that are dependencies for other things. It reinforces the single-responsibility principle, and it tells me (and other developers that might look at this code) that here be no implementation details, instead only representations. The code for all of these abstractions so far are as follows:
namespace helloserve.com.Domain
{
public interface IBlogDatabaseAdaptor
{
}
public interface IBlogOwner
{
}
public interface IBlogSyndication
{
}
}
namespace helloserve.com.Domain.Models
{
public class Blog
{
}
}
What do you notice here? There is literally nothing in the code.
What else do you notice here? There is a subtle difference between the project name and the different namespaces inside it: the namespaces omit the word ".Abstractions". The reason for this is simple - your consumer is interested in your domain, and from their perspective stuff that is public is available to them, regardless of if it’s an abstraction or not. They will call into BlogService to get an instance of type Blog, and for them it’s annoying to have two using clauses at the top, one with and another without the post-fix of ".Abstractions". This is also a standard that Microsoft follows in their Nuget packages through-out now. For example, if you are writing a class library and simply want to provide a method to register your services, all you need is access to IServiceCollection, which is in the Microsoft.Extensions.DependencyInjection.Abstractions package. However, when you need to actually call on the service collection implementation and build a IServiceProvider yourself, like in a console application startup, you need the whole nine yards which is the Microsoft.Extensions.DependencyInjection package. Those are two separate Nuget packages, the one is lightweight and the other has all the default implementations, but you only ever write
using Microsoft.Extensions.DependencyInjection regardless of which package you're including. This sort of naming convention discussion is part of your API’s design. And it is part of what makes good API. This example is specific to .NET, but the concept of good naming convention for your API is universal. And here, by following the standards, we align ourselves with the tools (like how Visual Studio intellisense will make our code discover-able) and with how the rest of the community (and those in your team and company) will perceive your code.
Filling in the blanks
Now that we’ve got a feel for the core domain solution structure, we can start to fill in the blanks. Again, let’s continue with the abstractions. We revisit the requirements again, but this time we look at the verbs. However don’t start typing away at your interfaces willy nilly. This is where we now have to start considering the specific use cases or user stories, and that comes with some process.
By test driven development
We take the first user story from the spec:
As an anonymous user I want to browse to a specific blog URL and see the blog content.
Functional requirements:
- The blog title should be in the url, with all encoded characters like punctuation removed.
- The blog title will be displayed as a heading
- The blog publish date will be displayed under the heading
- A blog article image or lead-in image will be displayed if it exists
- The blog content will be displayed
Non-functional requirements:
- The blog should load in less than 2 seconds
- The blog should scale correctly on all popular screen sizes
To satisfy this user story we need to get the blog content, title, all of it. Which parts of this user story is applicable to the BlogService? Which parts are about presentation? Which parts are about persistence? This is the most difficult bit of understanding your requirements. The requirement or story typically spans across your abstractions and touches on all your layers. If we were to create tasks for this one story we would have tasks for the UI, the service and the database. Until now we’ve only really designed the service, so let's just focus on that so long: The service should be able to supply a blog post representation given the title of the blog post. Lets implement that. We start with a unit test project and a unit test class.
[TestClass]
public class BlogServiceTests
{
[TestMethod]
public async Task Read_HasModel()
{
}
}
What we have here is a test class with a test method (I’m using MS Test here) as denoted by the attributes. The test method is called Read_HasModel since the verb that this story is related to is the read verb, and we want to assert that we get an instance of a blog back.
Red
Now, there are three parts to a unit test: arrange, act and assert. Typically referred to as AAA. However, I never start with arrange or act, because I want to always first think about what the result should be, how I will test before what I need to build. I also follow the Red/Green/Blue method, which means that we have to fail (red) first, so we have to get our asserts in first. In this case we want a blog entity. Let’s put that in.
[TestMethod]
public async Task Read_HasModel()
{
//arrange
//act
//assert
Assert.IsNotNull(result);
}
But where does result come from? That should be what the service gives me back, right? Let's put that in.
[TestMethod]
public async Task Read_HasModel()
{
//arrange
//act
Blog result = await service.Read(title);
//assert
Assert.IsNotNull(result);
}
So now we have something that takes a title and gives us a result, but what is that something? It is the BlogService of course, so let’s put that in.
[TestMethod]
public async Task Read_HasModel()
{
//arrange
var service = new BlogService();
string title = "";
//act
Blog result = await service.Read(title);
//assert
Assert.IsNotNull(result);
}
Is our unit test completed now? Pretty much, but we still have to do a few things. It doesn't compile yet, for a start. We add a reference to the domain project that it is supposed to test. Once the BlogService reference is resolved, we use the IDE tools to create the Read method on that service for us. Notice how we didn’t have to write any code for that.
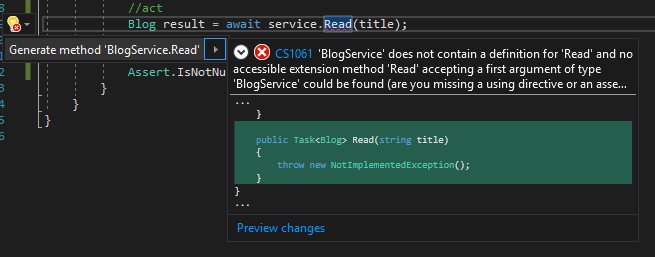
On a side note: notice how I didn’t use var result but was instead explicit about the type Blog of the result? This is on purpose. It’s not clear from the method call service.Read(title) what the type of the result is for someone that reads the code, and also the code completion could accurately type the result of the generated method. Had I instead used var result, it would simply have typed the method’s result as object, and that’s not something you want.
Now it compiles, so let's run the test. It fails with a NotImplementedException error detailed in the test result pane. This is because the code generation tool doesn’t know what to put in the method, so instead it makes it obvious and fails fast. That’s pretty cool, because failing fast is also really good API (we'll see more about that later).
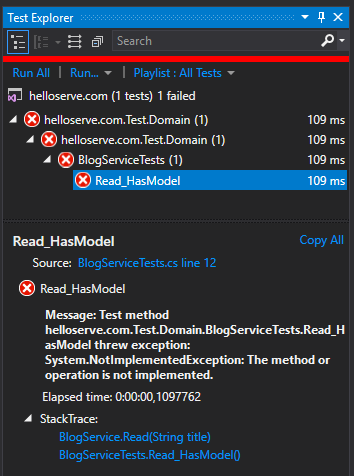
The unit test requires that we get a blog post entity. So let’s give it one. We update that Read method accordingly.
public async Task<Blog> Read(string title)
{
return await Task.FromResult(new Blog());
}
Green
Now our unit test passes. Finally we have moved from red to green, and crucially as per the process, we’ve only written enough code to pass the test. Let’s move to blue, and consider if there is any refactoring to do. At this point it doesn’t look like it - there is only one line of code!
Red
Now we need to go back to red by creating our second unit test as we work towards exhausting all the test cases. But what will we test? Let’s consider the first item of the requirements, about the blog title being in the URL. This is something a lot of blog sites do, in fact. Imagine you get a link from a friend to read something, but that link is https://blogpostplace.com/23546. You can’t see from that URL what it’s about. Instead, a link like https://blogpostplace.com/this_is_about_unit_testing is pretty clear (and also search engine friendly). What does that mean for our service though? If we use this kind of URL scheme the service has no way to locate the blog’s content using something like a blog ID; it only has the title. The title is the only input by which the content should be fetched from the database. So we need to verify that the service correctly passes it along to the database queries. We start with the asserts again so that we fail our unit test. We want to make sure that given a specific input, we get back a specific output. We also copy the rest from the previous unit test.
[TestMethod]
public async Task Read_Verify()
{
//arrange
var service = new BlogService();
string title = "";
//act
Blog result = await service.Read(title);
//assert
Assert.AreEqual("Hello Test!", result.Title);
}
It doesn’t build. So we again use the IDE’s code completion tools to generate us the Title property. We run our unit test again and it fails. How do we pass it? Let’s look at the Read method again, and change it to give the title a value.
public async Task<Blog> Read(string title)
{
return await Task.FromResult(new Blog() { Title = title });
}
Green
The unit test now passes, but there is one problem here. We’re passing in a value “Hello Test!” but according to the requirements the URL value will not have any punctuation or escaped characters. Our test value isn’t very realistic. Let’s fix that.
Red
string title = "hello_test";
Our unit test now fails again. The error reads Message: Assert.AreEqual failed. Expected:<Hello Test!>. Actual:<hello_test>. Well, we kind of expected this, because our Read method code simply puts the title in the parameter back into the Blog instance returned.
This change to the unit test is important however. Until now we’ve been using the unit tests mostly to write our code for us by using code completion features by way of the Red/Green/Blue flow. But now it is actually testing the first functional requirement, where the blog title from the URL contains no punctuation or other escaped characters, while the blog title that is returned is the real title to be displayed as the heading. We want to proceed to fix or write code to get it green again, but we have a problem. Given the URL title, we have no way to know how to reconstruct the real title. Of course not, because the URL title is supposed to be a stripped version which is simply input into a database query and not used for display purposes. This means that we will need to start looking at that database adaptor abstraction. Let’s give ourselves an instance of that, and use it to get a blog entry with a title instead of trying to create one with a title that we cannot reconstruct.
public class BlogService
{
readonly IBlogDatabaseAdaptor _dbAdaptor;
public BlogService(IBlogDatabaseAdaptor dbAdaptor)
{
_dbAdaptor = dbAdaptor;
}
public async Task<Blog> Read(string title)
{
return await _dbAdaptor.Read(title);
}
}
The database adaptor abstraction doesn’t contain a definition of that method we’re now calling, so we use code completion again to create it. Doing this will also require that we update the unit test class since the service now has a constructor parameter that we need to pass. But we can’t instantiate IBlogDatabaseAdaptor.
SOLID: L for Liskov Substitution
Here’s what we can do though. We can provide an implementation of that interface to be a substitute for the real thing during unit testing. This is referred to as a mock instance, or a fake instance. This principle says that any implementation (or subtype) of a type should be able to replace any other implementation of that same type, and the calling code should be none the wiser, e.g. the contract defined by the type (or interface in this case) is honored by either implementation. It is your duty to ensure that the substituted implementation conforms to the strong behavioral subtyping. Let’s construct such a mock inside the test project that we will substitute for the real thing.
public class BlogTestDatabaseAdaptor : IBlogDatabaseAdaptor
{
public Task Read(string title)
{
throw new System.NotImplementedException();
}
}
We can now pass an instance of this class to the service.
[TestMethod]
public async Task Read_Verify()
{
//arrange
var service = new BlogService(new BlogTestDatabaseAdaptor());
string title = "hello_test";
//act
Blog result = await service.Read(title);
//assert
Assert.AreEqual("Hello Test!", result.Title);
}
Now both tests fail! Oh no what have we done? We can see that both tests report a NotImplementedException in the test result pane. This is from our mock adaptor that the code completion put there. See how failing fast is good API?! We have to fix this mock’s method to help our specific test scenario. The first test expects an instance. Let’s do that.
public class BlogTestDatabaseAdaptor : IBlogDatabaseAdaptor
{
public async Task<Blog> Read(string title)
{
return await Task.FromResult(new Blog());
}
}
Notice how this is the exact same code as we had in our service’s Read method before? It has now emerged from our unit testing that this code we put in our service was supposed to go into the database adaptor. In other words, our database adaptor implementation is where new instances of Blog originates from, we shouldn't be "newing up" Blog instances in the domain layer. This passes the first test, so let’s look at the second test. It needs the title to be set.
public class BlogTestDatabaseAdaptor : IBlogDatabaseAdaptor
{
public async Task<Blog> Read(string title)
{
return await Task.FromResult(new Blog() { Title = "Hello Test!" });
}
}
Finally, both tests pass. But does it actually verify our required functionality? Can we confirm with confidence that the service's code calls the adaptor with the correct value? Let’s change the second test to a data test method.
Actually testing something
[DataTestMethod]
[DataRow("hello_test", "Hello Test!")]
[DataRow("title_two", "Title #2")]
public async Task Read_Verify(string paramTitle, string expectedTitle)
{
//arrange
var service = new BlogService(new BlogTestDatabaseAdaptor());
//act
Blog result = await _service.Read(paramTitle);
//assert
Assert.AreEqual(expectedTitle, result.Title);
}
What this does is pair a specific input, paramTitle, with an expected output, expectedTitle. Then it compares the actual output with the expected output. It passes for the first case, but not for the second case.
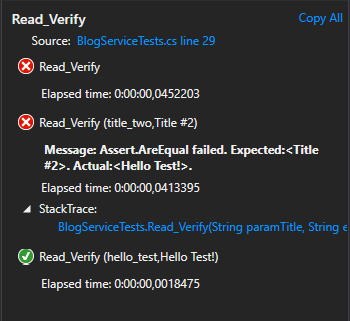
This is because our mock doesn’t help us to actually test that the parameter is correctly passed to the adaptor. The mock always returns the same output regardless of the input. So we weren’t actually testing anything before. We can fix this by changing the mock.
public class BlogTestDatabaseAdaptor : IBlogDatabaseAdaptor
{
public async Task<Blog> Read(string title)
{
switch (title)
{
case "hello_test":
return await Task.FromResult(new Blog() { Title = "Hello Test!" });
case "title_2":
return await Task.FromResult(new Blog() { Title = "Title #2" });
default:
return await Task.FromResult(new Blog());
}
}
}
Blue
Our unit tests again pass. Now we’re getting into the realm of test cases and setting up data to test specific scenarios. So let’s go to Blue again and consider our implementation. There’s a bit of shared code between the two tests, specifically the creation of the service. We can probably move that into a class property and just reference the property instead.
public BlogService Service => new BlogService(new BlogTestDatabaseAdaptor());
Scale
We’ve also got a nice and easy to understand mock adaptor that caters for two specific scenarios. This is a really good start, but it doesn’t scale. As the BlogService class becomes more complex you will find yourself constantly having to update the mock in order to support the new functionality, but also to not break the data already being used by other unit tests. Also, what’s the point of writing a mock like this which has so many lines of code if you could rather spend your time writing the actual implementation? This mock is similar to unit testing with an in-memory database. Entity Framework has great support for this and if you simply build the real implementation instead you could use that. But it suffers from the same problems as this kind of mock implementation. The only realistic way to unit test using a central mock or database is to set up specific scenarios for each unit test. In this context it means that no two unit tests will be able to test using the same blog title. In more complex systems where you have a userId, a departmentId, a couple of relationships between them and perhaps a few statuses, things get arduous to set up very quickly.
In order to solve this in a better way, let’s consider some of the available mocking frameworks. There are a few libraries available that helps us in this regard. I prefer to use Moq, but there is also NSubstitute and FakeItEasy that I know of. Let’s add it to our unit test class.
readonly Mock<IBlogDatabaseAdaptor> _dbAdaptorMock = new Mock<IBlogDatabaseAdaptor>();
public BlogService Service => new BlogService(_dbAdaptorMock.Object);
Red
If we test we see that both our unit tests now fail again. This is ok, because we substituted our old mock for _dbMockAdaptor.Object in the constructor call to the service. We’re now using the new mock that we set up with Moq, but it doesn’t yet know what it is supposed to do. We can easily configure it for the first unit test in the arrange section.
[TestMethod]
public async Task Read_HasModel()
{
//arrange
string title = "";
_dbAdaptorMock.Setup(x => x.Read(title)).ReturnsAsync(new Blog());
//act
Blog result = await Service.Read(title);
//assert
Assert.IsNotNull(result);
}
Here we've replaced our custom mock Read method with a quick Func<Blog> when we setup the mock object. I prefer to use mocks in this way because the arrangements contains the input and output within the test itself. For me this is a great way to illustrate the complexity and usage of a specific feature at a glance, as opposed to when the data setup lives elsewhere in a script or a hard coded class file (or in an in-memory database).
We’re still red on the other one, but the other test can be changed completely now. The Moq framework has a built-in way to verify a call to itself.
[TestMethod]
public async Task Read_Verify()
{
//arrange
var title = "hello_test";
//act
await Service.Read(title);
//assert
_dbAdaptorMock.Verify(x => x.Read(title));
}
Green
In this way we can directly verify that the adaptor was called specifically with the input that we expect. It doesn’t require any setup. But what about the title being returned I hear you ask? It doesn’t really come into play anymore. We wanted to confirm that the adaptor was called correctly, so previously we leveraged off of the returned titles as a way to ensure that our "use case" was satisfied. But we don’t need it anymore, so we’ll put it aside for now.
Blue
For the final Blue phase we notice that in fact, the tests are practically the same. Because of how this mocking framework works, the first test is also testing that the adaptor is called with the specific input provided (the blank title string). In this framework you have the option to do the setup using "any of type" parameters:
_dbAdaptorMock.Setup(x => x.Read(It.IsAny<string>())).ReturnsAsync(new Blog());
This would make any invocation of the Read call return a new empty Blog object. However the way we’ve written it, using the title variable explicitly, means that only the invocation with that specific value will give us that instance, all other invocations will return null. It is effectively testing that the adaptor is called correctly, just like the second test. So, which one do you prefer? I like the second one, but it doesn’t include checking the return type of the method. A developer is free to change the return type of the service’s Read method without breaking the second test. So let’s keep only the first one.
Conclusion
In this part we wrote our first unit tests, and I can hear you thinking that this was a very long blog post and a lot of effort for what ended up being a one line service method and only one unit test method. This is indeed a simple case, but it serves to illustrate a few things:
- How I leverage off of code completion features for a lot of the code that ended up being "real".
- We have executed the "real" code long before we have a working web API that can start up, or a database in place.
- Our understanding and design of the dependency model in our architecture was confirmed by using the abstractions and substituting a mock.
As your domain grows in complexity you will find that this is a much faster way of working. You can early on confirm with confidence that your code is working by defining all the required constraints of a scenario using the abstractions. Your unit tests will also always remain the vanguard of your code, protecting it from being changed in ways that break previously implemented features and functionality.